Arguments
in
the Standard File
Naming Conventions
Sample Analysis
Statistics By Time Range
Arguments to SampleAnalysis methods
Checking for Edit Areas
Global Thresholds and Variables
Scalar Analysis methods
Vector Analysis methods
DiscreteAnalysis
methods
Weather
Analysis methods
Algorithm for rankedWx and dominantWx
Text Rules Libraries for Narrative
Products
Setting Day and Night Times
Analysis-Driven Phrases
Arguments to Narrative methods
Checking
for Edit Areas
Global
Thresholds and Variables
Narrative
Phrases
Scalar Weather Element Phrases
Vector-Related Phrases (Wind and WindGust)
Sea Breeze Identification
Weather Phrases
Weather Subkey Attributes
"Primary" and "Mention"
Customizing Weather Phrases
Pop/Wx Consistency
Combined Element Phrases
Marine Phrases
Algorithm for WaveHeight
and WindWaveHgt Reporting
Fire Weather Phrases
Discrete Phrases (Headlines)
Narrative Strategies
Non-Linear Thresholds
DataValue
Extraction from the Grids
Unit Conversion
Standard and
Non-Standard Rounding
Range Adjustment
Null Values
Local
Effects
Local Effects and
Compound Phrases
Consolidation
Rules for Local Effects
Local Effect Examples
Null Values and Local
Effects
"Except" vs. "Otherwise"
wording
More
Local Effect Area Features
Local
Effects for Snow Accumulation and Total Snow Accumulation -- Using a
Method for Checking the Local Effect Threshold
Local
Effects for the Combined SkyPopWx Phrase
Period Combining
Phrase Consolidation
Phrase Ordering
"Until" Phrasing
Visibility
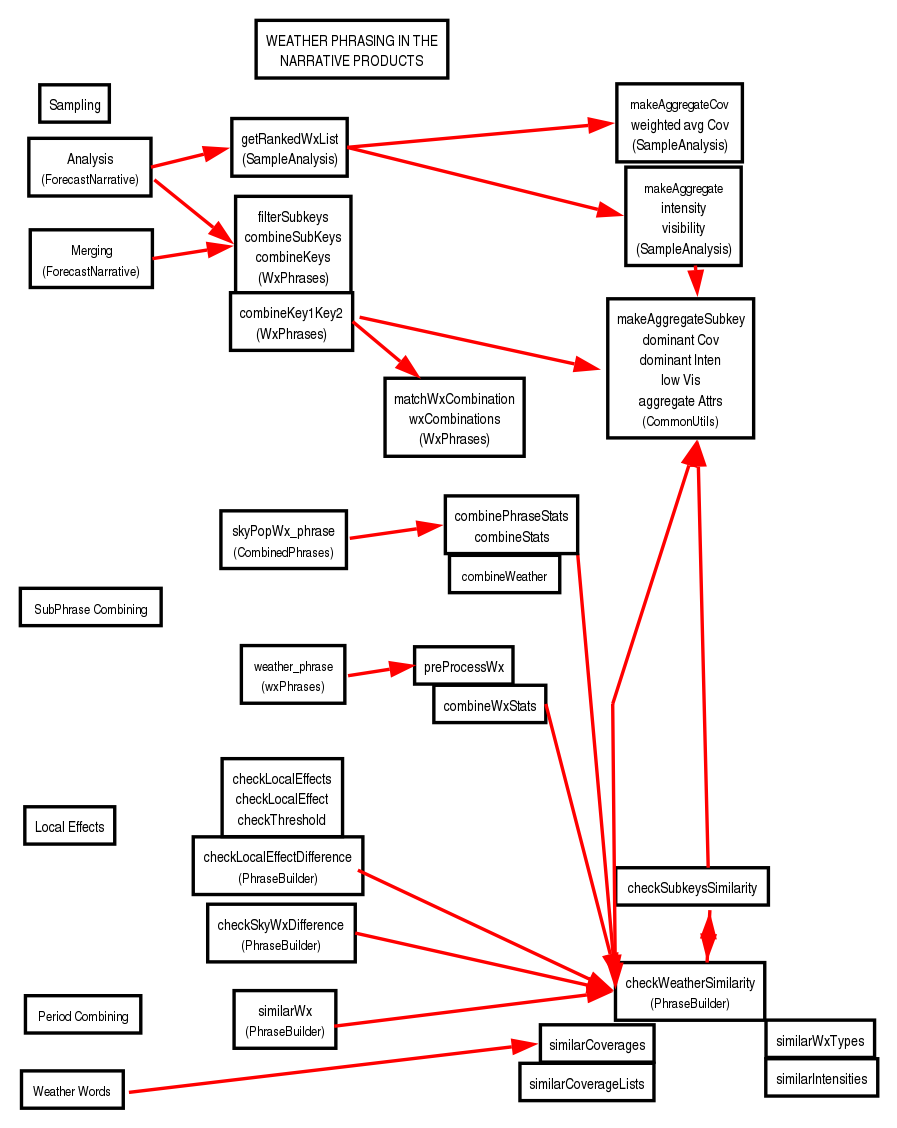
Weather Phrasing
Appendix A: Local Effects
Design
| ARGUMENT | ACCESSING INFORMATION |
| argDict | Dictionary containing system information about the product being created. In most cases, you will not need to access information within argDict, but it must be passed for internal system use. |
| fcst | The text string representing the product. It will be in a partially completed state as it is passed to each method in turn. Be sure to "return fcst" at the end of a method that is passed the fcst. |
| editArea | Contains the name and polygon points that define an edit
area. editAreaName = editArea.id().name() |
| areaLabel | The label given to the current edit area (or current combination of areas). This label is defined via the "defaultEditAreas" entries OR within the Combinations file entries. |
| timeRange | Time Range over which statistics are being generated.
This is always in GMT. timeRange.startTime() timeRange.startTime().day(), timeRange.startTime().month(), timeRange.startTime().hour() timeRange.endTime() |
| METHOD SUFFIXES | METHOD RETURN VALUE |
| _dict | Python dictionary |
| _difference | a difference in weather values e.g. vector_mag_differenceis used to determine if wind magnitudes are significantly different |
| _element | weather element name e.g. "WindWaveHgt" returned as the seasWindWave_element |
| _flag | 0 or 1 |
| _list | Python list |
| _percentage | number between 0 and 100 |
| _phrase | text string phrase |
| _phrase_connector | text string for connecting phrases e.g. " then " as in "Mostly cloudy in the morning then clearing." |
| _threshold | weather element value |
| _weight | number between 0 and 1 |
| _valueStr | string representing a weather element value |
| _valueList | list of thresholds corresponding to value strings for weather element values |
| _value_connector | text string for connecting values e.g. " to " as in "25 to 35 mph" |
| _nlValue | This suffix indicates that the method can return either a single value, a method, OR a dictionary of (lowValue, highValue) : returnValue entries. See the section on "Non-linear Thresholds" for more information. |
"analysisList" : [
("MaxT", self.avg),
]
The result of the analysis will be a simple average value for the entire time range being examined. Using the optional "divide" argument, the analysisList might look like this:
"analysisList" : [
("MaxT", self.avg, [6]),
]
In this instance, the time range will be divided into 6-hour sub-ranges and an average value for MaxT will be reported for each sub-range. This information will be reported as a list of tuples. For example, a 12-hour time range would produce:
[ (avg1, subRange1), (avg2, subRange2)]
The time range is divided from the endtime backward so that "odd" sub-ranges occur at the beginning of the time range. For example, suppose we are dividing an 8 hour time range into 6-hour sub-ranges. This will result in a 2-hour sub-range followed by a 6-hour sub-range.
The Text Rules methods are built to handle varying types of Sample Analyis return values.
If the time-divide argument is zero, the statistics will be reported "byTimeRange" returning a list of (statistics, subRange) tuples, one for each grid overlapping timeRange being examined.
In summary, the following table shows analysisList methods and their
corresponding results:
| ANALYSIS LIST SPECIFICATION | RESULT |
| ("MinT", self.avg) | Average scalar value over the entire time range |
| ("MinT", self.avg, [0]) | List of (avg, subRange) tuples, one for each grid overlapping timeRange |
| ("MinT", self.avg, [3]) | TimeRange is divided into 3-hour sub-ranges and
returns: List of (avg, subRange) tuples, one for each sub-range |
| ("MinT", self.avg, [6]) | TimeRange is split into 6-hour sub-ranges and returns: List of (avg, subRange) tuples, one for each sub-range |
NOTE that if there is no data for ANY ONE of the subRanges, None is returned for the entire time range.
| ARGUMENT | ACCESSING INFORMATION |
| parmHisto | Weather Element: elementName =
parmHisto.parmID().parmName() Edit Area: editAreaName = parmHisto.area().id().name() |
| timeRange | Time Range over which statistics are being generated.
This is always in GMT. timeRange.startTime() timeRange.startTime().day(), timeRange.startTime().month(), timeRange.startTime().hour() timeRange.endTime() |
| componentName | Current Text Product component being analyzed |
GLOBAL THRESHOLDS AND VARIABLES
There are four categories of analysis methods: absolute, cumulative, standard deviation (stdDev) and moderated (percentage). The absolute and cumulative categories do not filter the sampled data. All statistics are based on the entire sampled data set. The standard deviation (stdDev) and moderated methods do filter the sampled data set, however. The stdDev methods ignore values that lie outside a configurable number of standard deviations from the mean. Low and high thresholds are defined independently. The moderated methods work exactly the same way as stdDev methods, except that they filter data based on a ranked percentage. Values are ranked, low to high, and outliers are excluded from the data set (e.g., the upper 10%).
Most analysis methods screen grids for temporal coverage of the
given time range before including their data values in the
analysis. The exceptions to this are the methods that
work with accumulative elements. The following table describes the
temporal coverage thresholds you can override for this screening
process. To override a threshold, simply copy the method from the
SampleAnalysis utility into your _Overrides file and change desired
values. Most methods weight grids temporally as well. Each grid
will contribute
proportional to its time duration for the sampled period.
Here is how the standard deviation SampleAnalysis methods work:
1) compute the standard deviation of all grid values
2) the stdDev_dict contains a
threshold, i.e., number of sigmas for each the min and the max
3) the routine calculates the min and max from the std deviation and
the sigmas
4) in some cases, the result may fall outside of the actual data
range. In this case, the returned values will be the min or max
of
the actual data points.
Here is how the moderated SampleAnalysis methods work:
1) compute the "histogram" of the data values
2) the moderated_dict gives a
percentage for min, and a percentage for max
3) we return values that are % percent from the min and % percent from
the max, not numerically, but from a sorted list. Thus if the
histogram is
4,4,5,6,7,8,9,10,15,19, and your percent is 20% for the min and 10% for
the max, you will pick out the 20% of the number and the 90% of the
number in the
sequence. Since there are exactly 10 samples in my exmaple, the
20% point will be 5, and the 90% point will be 15. It isn't
numerical.
Here is some further explanation (from Bill Schneider) on the moderated methods:
The moderated methods look at all the points in the grid, then they throw away highest (for max) or lowest (for min) percentage you have specified in the moderated dictionary. Then it uses the max or min of the remaining gridpoints.
So for example if you use moderatedMaximum for temperature and have
defined the moderated percentages fore temperature as (10,15) in the
dictionary, the method will take the grid points that have the highest
values and throw away the top 15 percent of them. The remaining maximum
value will be reported. For moderatedMinimum, the method will take the
grid points that have the lowest values and throw away 15 % of the
lowest values before reporting the minimum.
| METHOD | RETURN VALUE: |
| **avg | average value |
| **minMax | (min, max) |
| **minimum | minimum value |
| **maximum | maximum value |
| **median | median value for given time range |
| **medianRange | 2-value range around the median value for given time range |
| **mode | mode value for given time range |
| **modeRange | 2-value range around the mode value for given time range |
| firstAvg | average value for first grid only |
| firstMinMax | minmax value for the first grid only |
| minMaxAvg | (min, max, avg) |
| minMaxSum | ( min, max, sum) Time-weighted min/max/ave of the multiple grids overlapping the time range. This is used for rate-dependent weather elements such as QPF. |
| accumMinMax | (min, max, sum) Returns the min, max, and sum for rate-dependent weather elements such as QPF. |
| accumSum | sum Returns the sum for rate-dependent weather elements such as QPF. |
| **maxAvg | average value. Calculates the average value in each of the overlapping grids, and then returns the maximum of the averages. |
| **maxMode | Calculates the mode value in each of the overlapping grids, and thern returns the maximum of the modes. Before calculating the mode, the values are rounded to the nearest increment as given in the maxMode_increment_dict |
| **stdDevMaxAvg | average value. Calculates the average value after filtering by standard deviation and then returns the maximum of the averages. |
| **moderatedMaxAvg | average value. Calculates the average value after filtering by moderated (percentage) and then returns the maximum of the averages. |
| **stdDevAvg | average value after filtering based on stdDev |
| stdDevFirstAvg | average value for the first grid only |
| **stdDevMinMax | (min, max) min, max set at standard deviations around the mean. The stdDev_dict, defines the number of standard deviations to compute min, max around the mean. Default is 1.0 standard deviations. Both min and max can be defined independently per weather element. |
| **stdDevMin | same as stdDevMinMax except just returns the minimum value |
| **stdDevMax | same as stdDevMinMax except just returns the maximum value |
| stdDevFirstMinMax | (min,max) stdDevMinMax (see above) for the first grid only |
| **moderatedAvg | Returns the average value after filtering based on percentage defined in moderated_dict |
| **moderatedMinMax | (min, max) Returns the min and max values after filtering based on the percentage defined in moderated_dict. |
| **moderatedMin | same as moderatedMinMax except just returns the minimum |
| **moderatedMax | same as moderatedMinMax except just returns the maximum |
| moderatedFirstAvg | same as moderatedAvg except only the first grid is sampled |
| moderatedFirstMinMax | same as moderatedMinMax except only the first grid is sampled. |
| hourlyTemp | return hourly T values in tuples; returns a list of tuples: (avgValue, startHour) |
| binnedPercent | return a list of tuples representing bins and corresponding percentages of values in each bin. The bins are defined in the bins_dict.NOTE: When using this method, make sure you have grids covering the entire time range of interest so that the percentages which are time-weighted will add up to 100. |
Note: all vector directions are returned as numeric. You can set the vectorDirection_algorithm to be "Average" or "MostFrequent". It will then apply to all vector analysis methods.
| **vectorAvg | (mag, dir) |
| **vectorMinMax | ((minMag, maxMag), dir) |
| **vectorMin | (minMag, dir) |
| **vectorMax | (maxMag, dir) |
| vectorMagMinMax | (minMag, maxMag) |
| vectorMagMin | minMag |
| vectorMagMax | maxMag |
| **vectorMode | (mag, dir) |
| **vectorMedian | (mag, dir) |
| **vectorModeRange | ((minMag, maxMag), dir) |
| **vectorMedianRange | ((minMag, maxMag), dir) |
| **vectorStdDevAvg | (mag, dir) |
| **vectorStdDevMinMax | ((minMag, maxMag), dir) |
| **vectorStdDevMin | (minMag, dir) |
| **vectorStdDevMax | (maxMag, dir) |
| **vectorModeratedAvg | (mag, dir) |
| **vectorModeratedMinMax | ((minMag, maxMag), dir) |
| **vectorModeratedMin | (minMag, dir) |
| **vectorModeratedMax | (maxMag, dir) |
| vectorRange | (mag1, mag2, dir1, dir2) returns mag and dir for two specified periods |
| vectorBinnedPercent | return a list of tuples representing bins and corresponding percentages of magnitude values in each bin. The bins are defined in the bins_dict.NOTE: When using this method, make sure you have grids covering the entire time range of interest so that the percentages which are time-weighted will add up to 100. |
| METHOD | RETURN VALUE | THRESHOLDS AND VARIABLES (To override, find in SampleAnalysis and copy to Overrides file) |
| discreteTimeRangesByKey | List of (discreteKey, timeRange) pairs ordered in ascending order by timeRange and then by priority of discrete keys as defined in the serverConfig files. | discreteKey_coverage_percentage-- required coverage by discete key |
| discreteTimeRangesByKey_withAux | Same as above, but including the
auxiliary field |
|
| **dominantDiscreteValue | List of most common discrete keys ranked from most frequent to least frequent. | discreteKey_coverage_percentage-- required coverage by discete key dominantDiscreteKeys_threshold-- maximum number of discrete keys to be returned from dominantDiscreteValue cleanOutEmptyValues -- whether or not to leave <None> values out of list of keys |
| **dominantDiscreteValue_withAux | Same as above, but including the auxiliary field | |
| **rankedDiscreteValue | List of most common (discrete keys, rank) pairs listed from most frequent to least frequent. | discreteKey_coverage_percentage-- required coverage by discete key dominantDiscreteKeys_threshold-- maximum number of discrete keys to be returned from dominantDiscreteValue cleanOutEmptyValues -- whether or not to leave <None> values out of list of keys (default 0) |
| **rankedDiscreteValue_withAux | Same as above, but including the
auxiliary field |
|
| discrete_percentages | list of (discrete key, percentage) pairs. Time-weighted / areal-weighted percentage is calculated for all overlapping grids | None |
| discrete_percentages_withAux | Same as above, but including the auxiliary field |
| METHOD | RETURN VALUE | THRESHOLDS AND VARIABLES (To override, find in SampleAnalysis and copy to Overrides file) |
| **rankedWx |
list of (subkey, rank) pairs
found for a given time range. rank is based on temporal and areal
coverage of the subkey in the time range |
coverage_weights_dict - weights per coverage term wxkey_coverage_percentage-- areal coverage over the time period by weather key attribute_coverage_percentage-- areal coverage over the time period for attributes dominantKeys_threshold-- maximum number of weather keys to be returned from dominantWx aggregateCov_algorithm - can use highest ranked coverage or a weighted scheme cleanOutEmptyValues -- whether or not to leave <NoWx> values out of list of keys (default 0) |
| **dominantWx | list of subkeys found for the given time range | same as rankedWx |
The Text Rules and all of it's inherited libraries can be found in
the Utilities window of the Define Text Products Dialog.
This section describes the threshold, variable and phrase methods in
the
TextRules libraries to support Narrative Products. This
information will help you customize your narrative product by looking
up
the phrases that are being generated in the "phraseList" of your
product
components. For each weather element (or combinations of weather
elements), we list Example Phrases, corresponding SampleAnalysis
methods, and Thresholds and variables you can set to customize the
phrase.
def DAY(self):
return 6
def
NIGHT(self):
return 18
If a threshold or variable appears in bold, then it MUST be set in order for the phrase to appear.
| ARGUMENT | DESCRIPTION | ACCESSING INFORMATION |
| tree | Narrative tree contains the structure and information for the entire narrative product | tree.stats.get(elementName, timeRange, areaLabel, statLabel,
mergeMethod) -- allows you to get statistics e.g.
stats = tree.stats.get("Wind", timeRange, "CO_Boulder", "vectorMinMax", "List") productTimeRange = tree.getTimeRange() |
| node | The node of the tree at which we are currently executing methods. | The current time range: nodeTimeRange = node.getTimeRange() nodeStartTime = nodeTimeRange.startTime() The current edit area: The current product component, name, definition, or
position: To see if the current edit area (which could be a Combination)
contains any of a list of edit areas: The current phrase: The "getAncestor" method finds the first ancestor with the given attribute and returns the attribute's value. |
| elementName | Weather element name -- useful information for returning threshold or variable values based on weather element |
inlandWatersAreas = ["TampaBayWaters", "InlandWaters"]
if self.currentAreaContains(tree, inlandWatersAreas):
# Return a value for the inland waters areas
else:
# Return a value for the other areas
| THRESHOLD OR VARIABLE | DESCRIPTION | LIBRARY |
| phrase_descriptor_dict | Descriptor words for weather elements in phrases e.g. "North winds 5-10 mph." | ConfigVariables |
| phrase_connector_dict | Connecting words in phrases e.g. "North winds 5-10 mph becoming20-25 mph. | ConfigVariables |
| value_connector_dict | Connectors for ranges of values e.g. "North winds 5 to 10 mph." | ConfigVariables |
| units_descriptor_dict | Words for units used in reporting data values e.g. "North winds 5-10 knots." | ConfigVariables |
| timePeriod_descriptor_list | Phrases for sub-ranges of a time period e.g. "Partly cloudy in the afternoon." | TimeDescriptor |
| scalar_difference_nlValue_dict | If the difference between scalar
values for 2 sub-periods is greater than or equal to this value, the
different values will be noted in the phrase. |
ConfigVariables |
| vector_mag_difference_nlValue_dict vector_dir_difference_nlValue_dict |
If the difference between vector values for 2 sub-periods is greater than or equal to these values, the different values will be noted in the phrase. | ConfigVariables |
| ELEMENT | TEXT RULES METHOD |
EXAMPLE PHRASES | SAMPLE ANALYSIS |
THRESHOLDS AND VARIABLES (To override, find in ScalarPhrases or ConfigVariables and copy to Overrides file) |
ADD'L INFO |
| Hazards | makeHeadlinesPhrases | .WINTER STORM WARNING IN EFFECT |
No sampling by SampleAnalysis |
allowedHazards | Found in DiscretePhrases module |
| Sky | sky_phrase | "Partly cloudy in the morning, then clearing." |
Sky: **Scalar Stats **binnedPercent PoP: (optional) |
pop_sky_lower_threshold clearing_threshold sky_valueList sky_value areal_sky_flag areal_sky_value areal_skyPercentage areal_skyRelatedWx similarSkyWords_list reportIncreasingDecreasingSky_flag reportClearSkyForExtendedPeriod_flag |
|
| PoP | popMax_phrase | "Chance of snow 40 percent." |
PoP: **maxAvg | phrase_descriptor_dict for
"PoP" May use this method in the phrase_descriptor_dict: areal_or_chance_pop_descriptor units_descriptor_dict for "percent" pop_lower_threshold pop_upper_threshold wxQualifiedPoP_flag matchToWxInfo_dict |
|
| MaxT MinT |
reportTrends | "Warmer." "Much colder." |
MaxT, MinT avg, minMax, stdDevMinMax |
reportTrends_valueStr to set up thresholds for trend phrases Phrases are based on 24 hour prior statistics |
|
| MaxT MinT HeatIndex WindChill |
extremeTemps_phrase | "Very hot." "Hot." "Bitterly cold." |
MaxT, MinT, HeatIndex, WindChill: **ScalarStats | heatIndex_threshold windChill_threshold |
This phrase may be used in place of "reportTrends" |
| MinT | lows_phrase | "Lows in the lower 40s to lower 50s." | MinT: minmax stdDevMinMax |
phrase_descriptor_dict for
"lows" minimum_range_nlValue_dict maximum_range_nlValue_dict range_nlValue_dict tempPhrase_exceptions tempPhrase_boundary_dict |
Only generated if Night time |
| MaxT | highs_phrase | "Highs in the upper 70s to lower 80s." | MaxT: minMax stdDevMinMax |
phrase_descriptor_dict for
"highs" minimum_range_nlValue_dict maximum_range_nlValue_dict range_nlValue_dict tempPhrase_exceptions tempPhrase_boundary_dict |
Only generated if Day time |
| MinT | lows_range_phrase | "Lows 45 to 50." | MinT: minMax stdDevMinMax |
phrase_descriptor_dict for "lows" minimum_range_nlValue_dict maximum_range_nlValue_dict range_nlValue_dict value_connector_dict |
Only generated if Night time |
| MaxT | highs_ range_phrase | "Highs 70 to 75." | MaxT: minmax stdDevMinMax |
phrase_descriptor_dict for "highs" minimum_range_nlValue_dict maximum_range_nlValue_dict range_nlValue_dict value_connector_dict |
Only generated if Day time |
| MinT | extended_lows _phrase |
"Lows in the 40s." "Lows 55 to 65." |
MinT: firstAvg |
extended _temp_range | C11 only |
| MaxT | extended_highs _phrase |
"Highs in the 70s." "Highs 55 to 65." |
MaxT: avg |
extended _temp_range | C11 only |
| T MinT MaxT |
temp_trends | "Temperatures falling overnight." |
T: hourlyTemp MinT and MaxT: avg, minMax, stdDevMinMax |
temp_trend_threshold | NOTE: There is an alternate method for "temp_trends_words" in the ScalarPhrases module. |
| SnowAmt |
snow_phrase | "Snow accumulation 2 inches."
|
SnowAmt: accumMinMax |
phrase_descriptor_dict for
"SnowAmt" units_descriptor_dict for "inches" and "inch" pop_snow_lower_threshold increment_dict for "SnowAmt" |
|
| SnowAmt | descriptive_snow _phrase |
"Moderate snow accumulations." | SnowAmt: accumMinMax | ||
| StormTotalSnow |
stormTotalSnow_phrase |
"Storm total snow accumulation
around 9 inches." |
StormTotalSnow: accumMinMax |
phrase_descriptor_dictfor
"TotalSnow" units_descriptor_dict for "inches" and "inch" pop_snow_lower_threshold increment_dict for "SnowAmt" |
|
| SnowAmt |
total_snow_phrase |
"Total snow accumulation 6
inches." |
SnowAmt: accumMinMax |
phrase_descriptor_dictfor
"SnowAmt" units_descriptor_dict for "inches" and "inch" pop_snow_lower_threshold getSnowReportEndDay increment_dict for "SnowAmt" |
|
| SnowLevel | snowLevel_phrase | "Snow level 7600 feet." | SnowLevel: **ScalarStats | phrase_descriptor_dict for
"SnowLevel" units_descriptor_dict for "feet" pop_snowLevel_upper_threshold snowLevel_maximum_phrase snowLevel_upper_topo_percentage snowLevel_lower_topo_percentage increment_dict for "SnowLevel" |
Be sure and set the snowLevel_maximum_phrasefor your local area |
| IceAccum |
iceAccumulation_phrase |
"Ice accumulation of up to
one half inch." |
IceAccum: accumMinMax |
ice_accumulation_threshold phrase_descriptor_dict for "IceAccum" increment_dict for "IceAccum" |
|
| WindChill | windChill_phrase | "Wind chill readings 5 to 10." | WindChill: **ScalarStats T:minMax |
phrase_descriptor_dict for
"WindChill" windChill_threshold windChillTemp_difference windChill_range |
|
| WindChill | windBased_windChill_phrase | "Wind chill readings 5 to 10." | WindChill:**ScalarStats Wind: **VectorStats |
phrase_descriptor_dict for
"WindChill" windChill_threshold windChill_wind_threshold minimum_range_threshold_dict range_threshold_dict value_connector_dict windChill_range |
Checks against Wind instead of T |
| HeatIndex | heatIndex_phrase | "Heat index readings 10 to 15." | HeatIndex: **ScalarStats T: minMax |
phrase_descriptor_dict for
"HeatIndex" heatIndex_threshold heatIndexTemp_difference minimum_range_threshold_dict range_threshold_dict value_connector_dict |
|
| MinRH |
rh_phrase |
"Minimum RH 30 percent." |
**ScalarStats MinRH |
rh_threshold |
| ELEMENT | TEXT RULES METHOD |
EXAMPLE PHRASES |
SAMPLE ANALYSIS |
THRESHOLDS AND VARIABLES (To override, find in VectorRelatedPhrases or ConfigVariables and copy to Overrides file) |
ADD'L INFO |
| Wind | wind_phrase | "Northeast winds 5 to 15 mph in the afternoon."
"Southwest winds 5-15 mph."
|
Wind: **Vector Stats | phrase_descriptor_dict for
"Wind" units_descriptor_dict for "mph" value_connector_dict for "Wind" e.g. 5 to 10 mph increment for "Wind" e.g. round wind magnitudes to nearest 5 null_nlValue_dict first_null_phrase_dict null_phrase_dict maximum_range_nlValuefor
"Wind" e.g. do not report winds with more than a 5 mph range e.g. 5 to
10 mph Differences used for reporting Wind in different time
periods: phrase_connector_dict for "becoming", "increasing to", "decreasing to", "shifting to the" embedded_vector_descriptor_flag_dict -- default is 1 -- if 0, descriptor is first e.g. "Winds east 5 to 10 mph." include_timePeriod_descriptor_flag -- moderates the time qualification on the phrase
e.g.
"in the afternoon" |
mph |
| Wind | wind_withGust_phrase | "East winds 10 to 20 mph with gusts to around 70 mph in the night becoming southwest 5 to 10 mph in the early morning." | Wind: **Vector Stats for Wind Wind: **Vector MinMax (must be there as a secondary analysis method for comparison in the gust_phrase) WindGust: **Scalar Stats |
Same as above PLUS: phrase_descriptor_dict for "WindGust" gust_threshold -- gusts reported if above this threshold gust_wind_difference_threshold -- gust reported if difference between max Wind and WindGust is greater than this threshold useWindsForGusts_flag -- if a WindGust grid is not found, the absolute max wind will be used for gusts |
mph |
| Wind | marine_wind_phrase | "West winds 10 to 20 knots in the morning shifting to the southwest in the afternoon." | **Vector Stats | Same as for public_windRange_phrase except units_descriptor_dict for "kt" marine_wind_flag set to 1 for marine descriptors e.g. gales, storm force winds seaBreeze_thresholds and local effects areas (see below) marine_wind_descriptor for "Wind" phrase_connector_dict for "becoming", "rising to", "easing to", "veering", "backing", "becoming onshore" useWindsForGusts_flag -- if a WindGust grid is not found, the absolute max wind will be used for gusts |
knots
See description for SeaBreeze below |
| Wind | marine_wind _withGusts_phrase |
"East winds 10 to 20 knots with gusts to around 70 knots in the night veering southwest 5 to 10 knots in the early morning." | Wind: **Vector Stats Wind: **Vector MinMax (must be there for comparision in the Gust phrase) WindGust: **ScalarStats |
Same as above PLUS phrase_descriptor_dict for "WindGust" gust_threshold -- gust reported if above this threshold gust_wind_difference_threshold-- gust reported if difference between max Wind and WindGust is greater than this threshold |
knots |
| Wind | lake_wind_phrase | "Caution advised on area lakes." | Wind: **Vector Stats | lake_wind_areaNames
phrase_descriptor _dict for "lakeWinds" lake_wind_thresholds |
|
| Wind | wind_summary | "Breezy" "Windy" | Wind: **Vector Stats | vector_summary_valueStr | |
| WindGust | gust_phrase | "Gusts up to 70 mph." | WindGust: **Scalar Stats | phrase_descriptor_dict for
"WindGust" gust_threshold null_nlValue_dict first_null_phrase_dict null_phrase_dict gust_wind_difference_nlValue -- gust reported if difference between max Wind and
WindGust is greater than this threshold |
NW winds 15 to 25 knots becoming onshore 10 to 15 knots.
To set up sea breeze indentification, you need to:
"phraseList":[
# WINDS
self.marine_wind_withGusts_phrase,
# Alternative:
#self.marine_wind_phrase,
#self.gust_phrase,
# WAVES
self.wave_withPeriods_phrase,
# Alternative:
#self.wave_phrase,
# Optional:
self.chop_phrase,
# WEATHER
self.weather_phrase,
# SWELLS AND PERIODS
self.swell_withPeriods_phrase,
# Alternative:
#self.swell_phrase,
#self.period_phrase,
],
"intersectAreas" :[
("Wind", ["OffShoreArea", "OnShoreArea"]),
],
}
| ELEMENT | TEXT RULES METHOD |
EXAMPLE PHRASES |
SAMPLE ANALYSIS |
THRESHOLDS AND VARIABLES (To override, find in WxPhrases, PhraseBuilder, or ConfigVariables and copy to Overrides file) |
ADD'L INFO |
| Wx | weather_phrase | Wx: **rankedWx | Pop/Wx Consistency coveragePoP_value pop_related_flag pop_wx_lower_threshold pop-related Wx types are not reported if PoP is below this threshold Combining and consolidating filter_subkeys_flag set to filter subkeys by combining duplicates and
similar Wx types as specified in: Wording rankFuzzFactor (CommonUtils) rankWordingFuzzFactor include_timePeriod_descriptor_flag -- moderates the time qualification on the phrase e.g. "in the afternoon" |
See section below on the meaning of Weather Subkey Attributes
"Primary" and "Mention." See section below on Customizing Weather Phrases See the section on Handling Visibility |
|
| Wx | severeWeather_phrase | "Some thunderstorms may be severe." "Some storms could be severe with damaging hail." "Some storms could be severe with large hail and damaging winds possible." |
Wx:**rankedWx | |
Reports if there is T+ in the time period. Also reports large hail and damaging winds. |
| Wx | heavyPrecip_phrase | "Rain may be heavy at times." "Locally heavy rainfall possible." "Snow may be heavy at times." |
Wx: **rankedWx | phrase_descriptor_dict for
"heavyRainfall", "heavyRain", "heavySnow", "heavyPrecip" heavySnowTypes heavyOtherTypes |
Reports if intensity is + for R, RW, S, SW, IP, ZR, ZL, L |
| Wx |
heavyRain_phrase |
"Locally heavy rain possible." |
Wx: **rankedWx | phrase_descriptor_dict for "heavyRains" | Reports if T has attribute HvyRn |
| Wx | visibility_phrase | "Visibility less than 1 nautical mile." | Wx: **rankedWx | null_nlValue for "Visibility" below which visibility is not reported
phrase_descriptor for "Visibility" increment_nlValue for "Visibility" visibility_phrase_nlValue element_outUnits_dict for "Visibility" |
See the section on Handling Visibility |
def wxTypeDescriptors(self):
# This
is the list of coverages, wxTypes, intensities, attributes for which
special
#
weather type wording is desired. Wildcards (*) can be used to
match any value.
# If a
weather subkey is not found in this list, default wording
# will
be used from the Weather Definition in the server.
# The
format of each tuple is:
# (coverage, wxType, intensity, attribute,
weatherType
descriptor)
return
[
("*", "RW", "--", "*", "sprinkles"),
("*", "SW", "--", "*", "flurries"),
]
In many cases, more than one of these methods will have to be overridden to accomplish the desired result. We might have to "turn on" one kind of wording and "turn off" other default wording. In the above example, we have to "turn off" the default descriptor for "very light" using the wxIntensityDescriptors:
def
wxIntensityDescriptors(self):
# This
is the list of coverages, wxTypes, intensities, attribute for which
special
#
weather intensity wording is desired. Wildcards (*) can be used
to
match any value.
# If a
weather subkey is not found in this list, default wording
# will
be used from the Weather Definition in the server.
# The
format of each tuple is:
# (coverage, wxType, intensity, attribute, intensity
descriptor)
return
[
("*", "RW", "--", "*", ""),
("*", "RW", "-", "*", ""),
("*", "R", "--", "*", "very light"),
("*", "R", "-", "*", "light"),
("*", "R", "+", "*", "heavy"),
("*", "RW", "+", "*", "heavy"),
("*", "SW", "--", "*", ""),
("*", "SW", "-", "*", ""),
("*", "SW", "+", "*", "heavy"),
("*", "S", "--", "*", "very light"),
("*", "S", "-", "*", "light"),
("*", "S", "+", "*", "heavy"),
("*", "ZR", "--", "*", "light"),
("*", "ZR", "+", "*", "heavy"),
("*", "L", "*", "*", ""),
("*", "F", "+", "*", "dense"),
]
Suppose we want to report "heavy snow" as "snow...heavy at times", we would include the following in our Overrides file:
def wxTypeDescriptors(self):
list = TextRules.TextRules.wxTypeDescriptors(self)
list.append( ("*", "S", "+", "*",
"snow...heavy at times") )
return list
def
wxIntensityDescriptors(self):
list = TextRules.TextRules.wxIntensityDescriptors(self)
list.append( ("*", "S", "+", "")
return list
As another example, suppose we want to describe thunderstorms with an attribute of "dry" as "dry thunderstorms." Including the following in our Overrides file could accomplish this:
def wxTypeDescriptors(self):
list = TextRules.TextRules.wxTypeDescriptors(self)
list.append( ("*", "T", "*", "Dry", "dry
thunderstorms") )
return list
def
wxAttributeDescriptors(self):
list = TextRules.TextRules.wxAttributeDescriptors(self)
list.append( ("*", "T", "*", "Dry", "") )
return list
It is possible to specify a method instead of text string for the descriptor. For example, the default wxTypeDescriptor for rain showers uses a method as follows:
def wxTypeDescriptors(self):
return
[
("*", "SW", "--", "*", "flurries"),
("*", "RW", "*", "*", self.rainShowersDescriptor),
]
def
rainShowersDescriptor(self, tree, node, subkey):
if
subkey.intensity() == "--":
return "sprinkles"
if
tree is None:
return "showers"
t =
tree.stats.get(
"T", node.getTimeRange(),
node.getAreaLabel(), statLabel="minMax",
mergeMethod="Min")
if t
is None:
return "showers"
if t
< 40:
return "rain showers"
else:
return "showers"
These methods are used in Table products as well as Narratives. NOTE: IF you are working with a narrative product, you can include the "tree, node" arguments and use them to qualify your customizations. For example, we could check the node time range and qualify fog as "morning fog" as in the example below:
def wxTypeDescriptors(self,
tree, node):
list = TextRules.TextRules.wxTypeDescriptors(self)
# Find out what time range we are working with
timeRange = node.getTimeRange()
# See if this time range is for the Morning
# First, shift to Local time from GMT
timeRange = self.shiftedTimeRange(timeRange)
startHour = timeRange.startTime().hour()
endHour = timeRange.endTime().hour()
if startHour >= 6 and endHour <= 12:
list.append( ("*", "F", "*", "*", "morning fog") )
return list
For more information on customizing Weather Phrases, see the
sections on Weather
Phrasing and
Phrase
Consolidation.
| ELEMENT | TEXT RULES METHOD |
EXAMPLE PHRASES |
SAMPLE ANALYSIS |
THRESHOLDS AND VARIABLES (To override, find in ConfigVariables, WxPhrases, or CombinedPhrases and copy to Overrides file) |
ADD'L INFO |
| Sky, PoP, Wx | skyPopWx_phrase | "Partly cloudy with a 20 percent chance of showers and
thunderstorms." "Sunny in the morning then partly cloudy with a 20 percent chance of rain showers in the afternoon." |
Wx:**rankedWx (See add'l info). Sky: **median PoP: **binnedPercent, |
The same thresholds and variables described for the weather_phrase apply to this combined phrase. In addition: useCombinedSkyPopWx useSkyPopWx_consolidation sky_valueList matchToWxInfo_dict |
NOTE: You should also include the
sky_phrase, weather_phrase, and popMax_phrase in your phraseList when
you are using the skyPopWx_phrase.
For more information on the algorithm used and examples, see the documentation in the CombinedPhrases module. |
| Wx, Sky | weather_orSky_phrase | If no weather, then return sky phrase | Sky: **median Wx: **rankedWx |
same as for weather_phrase and sky_phrase |
| ELEMENT | TEXT RULES METHOD |
EXAMPLE PHRASES |
SAMPLE ANALYSIS |
THRESHOLDS AND VARIABLES (To override, find in ConfigVariables or MarinePhrases and copy to Overrides file) |
ADD'L INFO |
| WaveHeight WindWaveHgt |
wave_phrase | "Combined seas 15 to 25 feet." "Wind waves 5 feet." |
WaveHeight or WindWaveHeight: ** Scalar Stats |
maximum_range_nlValue inlandWatersAreas inlandWatersWave_elementl waveHeight_wind_threshold combinedSeas_threshold seasWaveHeight_element seasWindWave_element noWaveHeight_phrase null_nlValue_dict first_null_phrase_dict null_phrase_dict include_timePeriod_descriptor_flag -- moderates the time qualification on the phrase e.g. "in the afternoon" |
See algorithm below |
| WaveHeight WindWaveHgt |
wave_withPeriod _phrase |
"Combined seas 15 to 25 feet dominant period 11 seconds." | Same as above PLUS: Period: **Scalar Stats Period2: **Scalar Stats |
same as above PLUS phrase_descriptor_dict for "dominant period" units_descriptor_dict for "ft" |
See algorithm below |
| Wind | see Wind and WindGust Phrases above | ||||
| Wind | chop_phrase | "Bay and inland waters a light chop." | Wind: **Vector Stats | phrase_descriptor_dict for
"chop" include_timePeriod_descriptor_flag -- moderates the time qualification on the phrase e.g. "in the afternoon" |
|
| Swell | swell_phrase | "Northeast swells 5 to 10 feet and 10 to 15 feet." | Swell: **Vector Stats Swell2: **Vector Stats Wind: **Vector Stats |
phrase_descriptor_dict for
"Swell" units_descriptor_dict for "ft" units_descriptor_dict for "foot" value_connector_dict for "Swell" e.g. 5 to 10 feet increment for "Swell" e.g. round swell magnitudes to nearest 1 null_nlValue_dict maximum_range_nlValue_dict
waveHeight_wind_threshold vector_mag_difference_nlValue_dict
e.g. 2 feet phrase_connector_dict for "becoming", "increasing to", "decreasing to", "shifting to the" embedded_vector_descriptor_flag_dict -- default is 1 -- if 0, descriptor is first e.g. "Swells east 5 to 10 feet." include_timePeriod_descriptor_flag -- moderates the time qualification on the phrase e.g. "in the afternoon" |
Note: The Swell phrase will not be produced for InlandWaters areas OR if a "seas" wave phrase is produced (See algorithm below.) |
| Swell | swell_withPeriod _phrase |
"Northeast swells 5 to 10 feet at 9 seconds and 10 to 15 feet at 12 seconds." | Swell: **Vector Stats Swell2: **Vector Stats Period: **Scalar Stats Period2: **Scalar Stats Wind: **Vector Stats |
Same as above PLUS: phrase_descriptor_dict for "Period" units_descriptor for "seconds" |
|
| Period | period_phrase | "Period 15 seconds." | Period: **Scalar Stats | phrase_descriptor_dict
for "Period" units_descriptor for "seconds" include_timePeriod_descriptor_flag -- moderates the time qualification on the phrase e.g. "in the afternoon" |
| ELEMENT | TEXT RULES METHOD |
EXAMPLE PHRASES |
SAMPLE ANALYSIS |
THRESHOLDS AND VARIABLES (To override, find in ConfigVariables orFirePhrases and copy to Overrides file) |
ADD'L INFO |
| CWR | cwr_phrase | CHC OF WETTING RAIN....20 percent | CWR: **ScalarStats | phrase_descriptor_dict | |
| Dispersion | smokeDispersal_phrase | SMOKE DISPERSAL.... | Dispersion: **ScalarStats | phrase_descriptor_dict smokeDispersal_valueStr |
|
| Haines | haines_phrase | HAINES INDEX...3 Very low potential for large plume dominated fire growth. | Haines: **ScalarStats | phrase_descriptor_dict hainesDict |
|
| LAL | lal_phrase | LAL...2. | LAL: avg [0] | phrase_descriptor_dict | |
| MaxRH | humidity_recovery_phrase | HUMIDITY RECOVERY...POOR | MaxRH: mode | phrase_descriptor_dict humidityRecovery_percentage humidityRecovery_valueList |
|
| MixHgt | mixingHgt_phrase | MIXING HEIGHT...600-1000 FT AGL | MixHgt: **ScalarStats | phrase_descriptor_dict | |
| Sky/Wx | skyWeather_byTimeRange_compoundPhrase | SKY/WEATHER...Mostly sunny until 1100...then partly cloudy. Chance of showers. | Sky: **Scalar Stats Wx: **dominantWx |
phrase_descriptor_dict includeSkyRanges_flag All the thresholds and varables from the weather_phrase and the fireSky_phrase apply |
To change the format of the sky ranges, override the addSkyRange method from FirePhrases |
| TransWind | transportWind_phrase | TRANSPORT WINDS...West 3-10 mph. | TransWind: **Vector Stats | phrase_descriptor_dict | |
| Wind | fireWind_compoundPhrase | 20-FT WINDS...Winds northeast around 10 mph in the evening becoming light after midnight. | Wind20ft OR Wind: **VectorStats | phrase_descriptor_dict All the threhsolds and variables from the wind_summary and wind_phrase apply. |
If the Wind20ft grid is available, it is reported. Otherwise, the Wind grid values are multiplied by the windAdjustmentFactor(set in the Overrides file) and reported. |
| Variable | trend_DayOrNight_phrase | "24-HOUR TREND...2 degrees warmer." "24-HOUR TREND...10 percent wetter." |
MinT, MaxT: mode MinRH, MaxRH: mode Optional: IF the trend grids are present, they are used, otherwise, the MinT or MaxRH (nighttime) or MaxT or MinRH (daytime) grids are used. |
phrase_descriptor for
"higher", "lower", "missing", "unchanged" trend_threshold_dict units_descriptor |
Arguments: dayElement, nightElement, trendElement, indent_flag, endWithPeriod_flag The flags are set to 1 for FWF-type phrases. |
| Variable | dayOrNight_phrase | "MAX TEMPERATURE....45-55." "MIN HUMIDITY...........20-25." |
avg, minmax, stdDevMinMax, median, mode | minimum_range_threshold_dict
range_threshold_dict value_connector_dict |
Arguments: dayElement, nightElement, indent_flag,
endWithPeriod_flag These flags are set to 1 for FWF-type phrases. |
def ridgeValleyAreas(self, tree, node):
# List of edit area names
for which we want
# ridge/valley winds
reported:
#
# 20-FOOT WINDS...
#
VALLEYS/LWR SLOPES...
#
RIDGES/UPR SLOPES....
#
# e.g.
# return ["Area1"]
return []
Next, make sure you have edit areas defined for "Ridges" and "Valleys" to intersect with the current area. If you want to use different edit area names, you can include the following override (from the FirePhrases module) in your Overrides file:
def valleyRidgeAreaNames(self, tree, node):
# These are the areas for
valleys and ridges, respectively,
# to be intersected with the
current edit area for
# reporting valley winds and
ridge winds, respectively.
# NOTE: If you change these
area names, you will also
# need to change the names
in the FirePeriod "intersectAreas"
# section.
return "Valleys", "Ridges"
| ELEMENT | TEXT RULES METHOD |
EXAMPLE PHRASES | SAMPLE ANALYSIS |
THRESHOLDS AND VARIABLES (To override, find in designated module and copy to Overrides file) |
ADD'L INFO |
| Hazards | makeHeadlinePhrases |
.WINTER STORM WARNING IN EFFECT |
Not sampled by SampleAnalysis | allowedHazards |
Found in DiscretePhrases module |
threshold = self.nlValue(threshold, value)
Any variable that is named with the suffix _nlValue can operate in this way returning EITHER a single value or a dictionary of values. If a dictionary is returned, it is of the form:
{
'default':
<default value>,
(lowVal, highVal)
: <value>,
}
where lowVal and highVal consitute a range for applying the given
value. The lowVal is inclusive while the highVal is exclusive.
For example:
def
scalar_difference_nlValue_dict(self, tree, node):
#
Scalar difference. If the difference between scalar values
# for
2 sub-periods is greater than this value,
# the
different values will be noted in the phrase.
return
{
"WindGust": {
'default': 10,
(0, 30): 10,
(30, 50): 15,
(50, 200): 20,
},
}
In this case, if the WindGust is greater or equal to 0 and less than 30, the scalar_difference will be 10; if WindGust is greater or equal to 30 and less that 50, the scalar_difference will be 15; etc.
You always have the additional option of basing the return value on the current edit area. For example:
def
scalar_difference_nlValue_dict(self, tree, node):
#
Scalar difference. If the difference between scalar values
# for
2 sub-periods is greater than this value,
# the
different values will be noted in the phrase.
return
{
"WindGust": self.windGust_scalar_nlValue_difference,
}
def
windGust_scalar_nlValue_difference(self, tree, node):
mountains = ["Area1", "Area2"]
if self.currentAreaContains(tree, mountains):
return 15
else:
return {
'default': 10,
(0, 30): 10,
(31, 50): 15,
(51, 200): 20,
}
The method applying the threshold must do the following before using it:
threshold =
self.scalar_difference_threshold(
tree, node, element, element)
for each value to check:
curThreshold = self.nlValue(threshold, value)
# Use
curThreshold for the given value
def element_inUnits_dict(self, tree, node):
#
Dictionary of descriptors for various units
def
element_outUnits_dict(self, tree, node):
#
Dictionary of descriptors for various units
Example of standard rounding increment (from ZFP_<site>_Overrides file, overriding increment_nlValue_dict in ConfigVariables module):
def
increment_nlValue_dict(self, tree, node):
#
Increment for rounding values
#
Units depend on the product
dict =
TextRules.TextRules.increment_nlValue_dict(self, tree, node)
dict["Wind"] = 5
return
dict
Example of non-standard rounding method (found in ConfigVariables module):
def
rounding_method_dict(self, tree, node):
#
Special rounding methods
#
return
{
"Wind": self.marineRounding,
}
def marineRounding(self,
value, mode, increment, maxFlag):
#
Rounding for marine winds
mode =
"Nearest"
if
maxFlag:
if value > 30 and value < 34:
mode = "RoundDown"
elif value > 45 and value < 48:
mode = "RoundDown"
else:
mode = "Nearest"
return
self.round(value, mode, increment)
The basic premise of range adjustment is that you have to commit to the ranges you choose (and rounding increments as well) from the beginning of processing. In other words, we can't just slap on a range at the very end when we are building the phrase; ranges need to be applied from the moment the grids are analyzed so that phrase combining and period combining are comparing pre-adjusted values. Then, if we do combine two sub-phrases or two periods, we have to combine their statistics and, then re-apply the range adjustments to the new values. The system is set up to recognize these cases when you set the range values listed below.
The following variables are used to adjust the range reported for the data value:
def
range_nlValue_dict(self, tree, node):
# If
the range of values less than this amount, return as a single value
def
minimum_range_nlValue_dict(self, tree, node):
# This
threshold is the "smallest" min/max difference allowed between values
reported.
# For
example, if threshold is set to 5 for "MaxT", and the min value is 45
# and
the max value is 46, the range will be adjusted to at least a 5 degree
#
range e.g. 43-48. These are the values that are then submitted
for
phrasing
# such
as:
# HIGHS IN THE MID 40S
def
maximum_range_nlValue_dict(self, tree, node):
#
Maximum range to be reported within a phrase
# e.g. 5 to 10 mph
#
Units depend on the product
def
range_bias_nlValue_dict(self, tree, node):
#
"Min", "Average", "Max"
# Should the range be taken from the "min" "average" or "max"
value of the current range?
return
{'default': "Average"}
def
maximum_range_bias_nlValue_dict(self, tree, node):
#
"Min", "Average", "Max"
# Should the maximum_range be taken from the "min" "average" or
"max" value of the current range?
return
{
"default": "Average",
"Wind": "Max"
}
def
minimum_range_bias_nlValue_dict(self, tree, node):
#
"Min", "Average", "Max"
# Should the minimum_range be taken from the "min" "average" or
"max" value of the current range?
return
{
"default": "Average",
"Wind": "Max"
}
NOTE:
The range_nlValue
is applied first and thus supercedes range adjustments
(minimum/maximum ranges). So if your minimum or maximum ranges
are
not taking effect, check to make sure there is not a range_nlValue set
for the weather element in question.
Ranges are adjusted at several points in the processing of phrases:
To accomplish this, include the following in the Overrides file:
def maximum_range_nlValue_dict(self, tree, node):
#
Maximum range to be reported within a vector phrase
# e.g. 5 to 10 mph
#
Units depend on the product
dict =
TextRules.TextRules.maximum_range_nlValue_dict(self, tree, node)
mountainZones = ["area3"]
if
self.currentAreaContains(tree, mountainZones):
range = 10
else:
range = 5
dict["MaxT"] = range
dict["MinT"] = range
dict["MaxRH"] = range
dict["MinRH"] = range
return
dict
def
maximum_range_bias_nlValue_dict(self, tree, node):
#
"Min", "Average", "Max"
# Should the maximum_range be taken from the "min" "average" or
"max"
# value of the current range?
dict =
TextRules.TextRules.maximum_range_bias_nlValue_dict(self, tree, node)
dict["MaxT"] = "Max"
dict["MinT"] = "Min"
dict["MaxRH"] = "Max"
dict["MinRH"] = "Min"
return
dict
def
increment_nlValue_dict(self, tree, node):
#
Increment for rounding values
#
Units depend on the product
dict =
TextRules.TextRules.increment_nlValue_dict(self, tree, node)
dict["MaxT"] = 5
dict["MinT"] = 5
dict["MaxRH"] = 5
dict["MinRH"] = 5
return
dict
def
scalar_difference_nlValue_dict(self, tree, node):
#
Scalar difference. If the difference between scalar values
# for
2 sub-periods is greater than this value,
# the
different values will be noted in the phrase.
def
vector_mag_difference_nlValue_dict(self, tree, node):
#
Replaces WIND_THRESHOLD
#
Magnitude difference. If the difference between magnitudes
# for
sub-ranges is greater than this value,
# the
different magnitudes will be noted in the phrase.
#
Units can vary depending on the element and product
def null_nlValue_dict(self,
tree, node):
#
Magnitude threshold below which values are considered "null" and
not reported.
return
{
"Wind": 5, # mph
"TransWind": 0, # mph
"FreeWind": 0, # mph
"Swell": 5, # ft
"Swell2": 5, # ft
"WaveHeight": 3, # ft
}
You may specify the phrases that will be used to report Null values. These phrases may be the empty phrase, "". You may want to specify a different phrase if the the null value occurs for the entire time period or the for the first sub-phrase versus in subsequent sub-phrases. Here are the default null phrase dictionaries from the ConfigVariables module:
def
first_null_phrase_dict(self, tree, node):
#
Phrase to use if values THROUGHOUT the period or
# in
the first period are Null (i.e. below threshold OR NoWx)
#
E.g. LIGHT WINDS. or LIGHT
WINDS BECOMING N 5 MPH.
return
{
"Wind": "light winds",
"TransWind": "",
"FreeWind": "",
"Swell": "light swells",
"Swell2": "",
"Wx": "",
"WindGust": "",
"Wave": "2 feet or less",
}
def null_phrase_dict(self,
tree, node):
#
Phrase to use for null values in subPhrases other than the first
# Can
be an empty string
# E.g. "NORTH WINDS 20 to 25 KNOTS BECOMING LIGHT"
return
{
"Wind": "light",
"TransWind": "light",
"FreeWind": "light",
"Swell": "light",
"Swell2": "",
"Wx":"",
"WindGust": "",
"Wave": "2 feet or less",
}
def
Period_1(self):
return
{
"type": "component",
"methodList": [
self.orderPhrases,
self.assemblePhrases,
self.wordWrap,
],
"analysisList": [
("MinT", self.stdDevMinMax),
("MaxT", self.stdDevMinMax),
("T", self.hourlyTemp),
("Wind", self.vectorMedianRange, [6]),
("Wind", self.vectorMinMax, [6]),
("WindGust", self.avg, [6]),
],
"phraseList":[
self.wind_summary,
self.reportTrends,
#self.highs_phrase,
#self.lows_phrase,
(self.highs_phrase, self._tempLocalEffects_list()),
(self.lows_phrase, self._tempLocalEffects_list()),
#self.highs_range_phrase,
#self.lows_range_phrase,
#self.wind_withGusts_phrase,
(self.wind_withGusts_phrase,
self._windLocalEffects_list()),
],
"intersectAreas": [
# Areas listed by weather element that will be
# intersected with the current area then
# sampled and analysed.
# E.g. used in local effects methods.
("MaxT", ["Mountains", "Valleys"]),
("MinT", ["Mountains", "Valleys"]),
("Wind", ["Coast", "Inland"]),
("WindGust", ["Coast", "Inland"]),
]
def
_windLocalEffects_list(self):
leArea1 = self.LocalEffectArea("Coast", "near the coast")
leArea2 = self.LocalEffectArea("Inland", "inland")
return
[self.LocalEffect([leArea1, leArea2], 10, " and ")]
def
_tempLocalEffects_list(self):
leArea1 = self.LocalEffectArea("Valleys", "")
leArea2 = self.LocalEffectArea("Mountains", "in the mountains")
return
[self.LocalEffect([leArea1, leArea2], 8, "...except ")]
As a result, the system will automatically calculate the intersection of the Mountains, Valleys, (for MaxT, MinT) and Coast, Inland (for Wind and WindGust) areas with each edit area as it processes it. Sampling and Analysis statistics will be calculated for both intersection areas for the appropriate weather elements. Then, the local effects phrase can examine the statistics for differences and report according to the methods and words given in the local effects definition. For example, the following phrases could be generated depending on the data:
"Highs 45-55."
"Highs 45-55...except 35-45
above timberline."
"North winds 20 mph."
"North winds 20 mph near the
coast and west winds 10 mph inland."
"Near the coast...North winds
20 mph becoming 10 mph in the afternoon. Inland...North winds 10 mph
becoming light in the afternoon."
def
skyWeather_byTimeRange_compoundPhrase(self):
return
{
"phraseList": [
self.fireSky_phrase
#self.weather_phrase,
(self.weather_phrase, self._generalLocalEffects_list()),
],
"phraseMethods": [
self.assembleSentences,
self.skyWeather_finishUp,
],
}
def
_generalLocalEffects_list(self):
leArea1 = self.LocalEffectArea("Coast", "on the coast")
leArea2 = self.LocalEffectArea("Inland", "inland")
leArea3 = self.LocalEffectArea("City", "in the city")
return
[self.LocalEffect([leArea1, leArea2, leArea3], 5, " ")]
Remember, as always, to include the local effect areas in the "intersectAreas" list within the component definition:
def
getFirePeriod_intersectAreas(self):
return
[
("MinT", ["BelowElev", "AboveElev"]),
("MaxT", ["BelowElev", "AboveElev"]),
("MinRH", ["BelowElev", "AboveElev"]),
("MaxRH", ["BelowElev", "AboveElev"]),
("RH", ["BelowElev", "AboveElev"]),
("Wx", ["BelowElev", "AboveElev"]),
]
Set Up:
def
_windLocalEffects_list(self):
srnInland = self.LocalEffectArea("Inland","")
srnBeaches = self.LocalEffectArea("Beaches","at the beaches")
return
[self.LocalEffect([srnInland, srnBeaches], 5, "...except ")]
The local effect descriptor will appear at the end of the sentence IF there is only one subphrase.
SOUTHWEST WINDS 25 TO 35 MPH AT THE BEACHES.
Otherwise, the sentence would be ambiguous:
SOUTHWEST WINDS 25 TO 35 MPH
INCREASING TO 40 TO 50
MPH IN THE AFTERNOON AT THE
BEACHES.
So the system produces:
AT THE BEACHES...SOUTHWEST
WINDS 25 TO 35 MPH INCREASING TO 40 TO 50
MPH IN THE AFTERNOON.
Null values and Wx: For periods in which you have Local Effects for Wx, you might want to specify afirst_null_nlValue and null_nlValue of "dry" so that the local effect can be correctly reported. For example:
def null_nlValue_dict(self,
tree, node):
# Descriptors for phrases
dict = TextRules.TextRules.null_nlValue_dict(self, tree, node)
componentName = node.getComponentName()
if componentName == "Period_1":
dict[Wx"] = "dry"
return dict
Then you will get phrases like:
SCATTERED SHOWERS...EXCEPT DRY IN THE BLUE MOUNTAINS.
instead of just:
SCATTERED SHOWERS.
def
_windLocalEffects_list(self):
srnInland = self.LocalEffectArea("BelowElev","")
srnBeaches = self.LocalEffectArea("AboveElev","at the beaches")
return
[self.LocalEffect([srnInland, srnBeaches], 5, "...except ")]
SOUTHWEST WINDS 5 TO 15 MPH...EXCEPT SOUTHWEST 25 TO 35 MPH AT THE BEACHES.
SOUTHWEST WINDS 5 TO 15 MPH. AT THE BEACHES...SOUTHWEST WINDS 25 TO
35 MPH INCREASING TO 40 TO 50 MPH IN THE AFTERNOON.
Set-up:
def
_windLocalEffects_list(self):
srnInland = self.LocalEffectArea("BelowElev","", "inland" )
srnBeaches = self.LocalEffectArea("AboveElev","at the beaches")
return
[self.LocalEffect([srnBeaches, srnInland,], 5, "...otherwise ")]
SOUTHWEST WINDS 25 TO 35 MPH AT THE BEACHES...OTHERWISE SOUTHWEST 5
TO
15 MPH.
AT THE BEACHES...SOUTHWEST WINDS 25 TO 35 MPH INCREASING TO 40 TO 50
MPH IN THE AFTERNOON. INLAND...SOUTHWEST WINDS 5 TO 15 MPH.
Set-up:
In the product component definition, we specify the local effects list as a method rather returning a list. This is necessary since we want to define the list "on-the-fly" based on the current edit area:
(self.highs_phrase, self._tempLocalEffects_list),
(self.lows_phrase, self._tempLocalEffects_list),
Then we add in the additonal areas to be sampled and analyzed:
"additionalAreas": [
# Areas listed by weather element that will be
# intersected with the current area then
# sampled and analyzed.
# E.g. used in local effects methods.
("MaxT", ["Benches", "Rush_Valley"]),
("MinT", ["Benches", "Rush_Valley"]),
],
Finally, we provide the method for defining the local effects list "on-the-fly."
def
_tempLocalEffects_list(self, tree, node):
if
self.currentAreaContains(tree, ["area1"]):
leArea1 = self.LocalEffectArea(
"__Current__","",intersectFlag=0)
leArea2 = self.LocalEffectArea("Rush_Valley",
"in the rush valley", intersectFlag=0)
leArea3 = self.LocalEffectArea(
"Benches", "in the benches",intersectFlag=0)
return [
self.LocalEffect([leArea1,leArea2],5,"...except "),
self.LocalEffect([leArea1,leArea3],5,"...except "),
]
else:
return []
Note that the Rush Valley will be checked first. If a local effect is found, it will be reported:
HIGHS IN THE UPPER 50S...EXCEPT IN THE UPPER 20S TO UPPER 40S IN THE RUSH VALLEY.
If not, the Benches will be checked and if a local effect is found, it will be reported:
HIGHS IN THE UPPER 50S...EXCEPT IN THE UPPER 20S TO UPPER 40S IN THE BENCHES.
Finally, if neither area triggers a local effect, a simple phrase will be reported:
HIGHS IN THE UPPER 50S.
SNOW ACCUMULATION 4 INCHES...EXCEPT 7 INCHES
ABOVE
TIMBERLINE. TOTAL SNOW ACCUMULATION 9
INCHES...EXCEPT 18 INCHES
ABOVE TIMBERLINE.
In your overrides file, you must override the product component(s) for which you want to report local effects for the snow_phrase and/or total_snow_phrase. In these component definitions, specify the local effect as follows:
(self.snow_phrase,self._snowAmtLocalEffects_list()),
(self.total_snow_phrase,self._totalSnowAmtLocalEffects_list()),
Next, add the "intersectAreas" to these components for SnowAmt and IceAmt (note that IceAmt is handled by the SnowAmt phrase):
"intersectAreas": [
# Areas listed by weather element that will be
# intersected with the current area then
# sampled and analysed.
# E.g. used in local effects methods.
("SnowAmt", ["BelowElev", "AboveElev"]),
("IceAmt", ["BelowElev", "AboveElev"]),
],
IMPORTANT NOTE: The total_snow_phrase looks AHEAD one period for information about snow ending (SnowAmt = 0). Therefore, you must include the "intersectAreas" in the component FOLLOWING the ones in which you are specifying a local effect for the total_snow_phrase. For example, in the ZFP_<site>_Overrides file using the 10-503 directive, if I set up a total_snow_phrase local effect for Period_1 and Period_2_3, I must also include the "intersectAreas" for Period_4_5.
Finally, include the following local effect lists in your Overrides file:
def
_snowAmtLocalEffects_list(self):
leArea1 = self.LocalEffectArea("BelowElev", "")
leArea2 = self.LocalEffectArea("AboveElev", "above timberline")
return
[self.LocalEffect([leArea1, leArea2], 2, "...except ")]
def
_totalSnowAmtLocalEffects_list(self):
leArea1 = self.LocalEffectArea("BelowElev", "")
leArea2 = self.LocalEffectArea("AboveElev", "above timberline")
return
[self.LocalEffect(
[leArea1, leArea2], self._checkTotalSnow, "...except ")]
def _checkTotalSnow(self,
tree, node, localEffect, leArea1Label, leArea2Label):
totalSnow1 = self.getTotalSnow(tree, node, leArea1Label)
totalSnow2 = self.getTotalSnow(tree, node, leArea2Label)
if
totalSnow1 is None or totalSnow2 is None:
return 0
if
abs(totalSnow1 - totalSnow2) > 3:
return 1
return
0
"phraseList":[
(self.sky_phrase, self._skyLocalEffects_list()),
(self.skyPopWx_phrase, self._skyPopWxLocalEffects_list()),
(self.weather_phrase,self._wxLocalEffects_list()),
(self.popMax_phrase, self._popLocalEffects_list()),
...
],
And also within the product component definition:
"intersectAreas": [
("Sky", ["AboveElev", "BelowElev"]),
("Wx", ["AboveElev", "BelowElev"]),
("PoP", ["AboveElev", "BelowElev"]),
],
Definition["periodCombining"]
= 1 # If 1, do period combining
Period combining is set up by methods found in the PhraseBuilder module:
1) If the periodCombining flag is set to 1 in the product, we add a
method to the product narrative tree top level node called
"combineComponents" (in PhraseBuilder module).
2) The "combineComponents" method is called at the top of the tree and
compares all consecutive components for similarity. Also, we are
only combining components that begin 36 hours after the issuance time
of the product.
3) If two components are deemed similar (according to the "periodCombining_elementList" (in
ConfigVariables)), then the component nodes are collapsed into one
node with the time range spanning the original nodes.
4) From here all phrases and processing pretty much the same as it
would have been for the original nodes. To simplify combined
period
phrasing, there is a threshold "collapsedSubPhrase_hours"
(in ConfigVariables) which is set to 12 hours as the default. If the
period is longer than these hours, subphrases will automatically be
collapsed.
Periods can be combined providing the differences between the
adjacent periods are small. There is one method per weather
element that determines whether two periods should be combined or
not. These methods are found in the PhraseBuilder module.
Each of them begin with "similar" followed by the weather element
name. The table below shows the methods that have been
implemented
thus far and their thresholds.
| Element Name as listed in the periodCombining_elementList | Method Name (in PhraseBuilder module) | Thresholds |
| Sky | similarSky | Sky words are similar |
| Wind | similarWind | mag within 10 knots dir within 45 degrees |
| Wx | similarWx | Identical wx keys per each analyzed sub-range |
| PoP |
similarPoP |
PoPs are equal or both below pop_lower_threshold or both above pop_upper_threshold |
| MaxT |
similarMaxT | MaxT within 5 degrees |
| MinT | similarMinT | MinT within 5 degrees |
| WaveHeight |
similarWaveHeight | WaveHeights within 4 feet |
| DiurnalSkyWx | similarDiurnalSkyWx | DiurnalSkyWx will combine if
there is a diurnal pattern of sky and wx. For example, "CLOUDY IN
THE NIGHT AND MORNING...OTHERWISE CLEAR." or "LOW CLOUDS AND FOG IN THE
NIGHT AND MORNING...OTHERWISE CLEAR." Note that it will also combine if the sky and wx are similar without a diurnal pattern. |
Each of these methods can be overridden in your Overrides file. In general, the threshold values are defined near the top of the method, so you won't need to hunt for them or change them in several places. If you desire to change the thresholds, copy the method into your Overrides file and modify the threshold value. You can also modify the algorithm, if you like. The default method retrieves the statistics and examines them to see if the values between each component are close enough to combine. You will likely want to leave the code that retrieves the statistics unmodified. But you can choose to change the logic that decides if the values are "similar".
When components are collapsed, we do not want phrases to have detailed sub-phrases as we would in a normal 12-hour period. Sub-phrases are then automatically collapsed if the combined period exceeds the collapsedSubPhrase_hours found in the ConfigVariables module. When sub-phrases are collapsed, the data is summarized according to the mergeMethod for the weather element being collapsed. These settings can be overridden in your Overrides file.
def
collapseSubPhrase_hours_dict(self, tree, node):
# If
the period is longer than these hours, subphrases will automatically
# be
collapsed.
return
{
"otherwise": 24,
#"Wx": 24,
}
def mergeMethod_dict(self,
tree, node):
#
Designates the mergeMethod to use when sub-phrases are automatically
collapsed.
return
{
"otherwise": "Average",
"MinT": "Min",
"MaxT": "Max",
"PoP": "Max",
"Wx": "List", # Still want Wx to be broken out
}
Definitions: Phrases are composed of sub-phrases depending on the temporal resolution of the statistics. For example, the Wind phrase in the ZFP is composed of 2 6-hour sub-phrases, e.g. "North wind 10-15 mph increasing to 20 mph in the afternoon." A phrase can report on multiple elements (e.g. Wind and WindGust). "North wind 10-15 mph with gusts up to 35 mph." Weather elements in these phrases are considered "primary" and "secondary".
.TODAY...STRONG WINDS. THUNDERSTORMS WITH
HEAVY RAINFALL. HIGHS
AROUND 80. SOUTHEAST WINDS AROUND 70 MPH BECOMING
SOUTH AROUND 105
MPH IN THE AFTERNOON.
The winds are the most dominant feature and thus you might want to move the "wind_withGusts_phrase" closer to the beginning of the forecast. To re-order phrases on-the-fly, follow steps similar to this example:
--Make sure the Product Component Definition for any Periods in which you'd like to order the phrases has the method, "orderPhrases", prior to "assembleSubPhrases":
def Period_1(self):
component = {
"type": "component",
"methodList": [
self.orderPhrases,
self.assemblePhrases,
self.wordWrap,
],
....
--Modify the "orderPhrases"(PhraseBuilder) method, for example:
def orderPhrases(self,
tree, component):
reorderList = []
timeRange = component.getTimeRange()
areaLabel = component.getAreaLabel()
#
Put in some logic to see if you want to re-arrange the order
# of
the phrases. For example:
#
Check for high winds
windMax, dir = tree.stats.get("Wind", timeRange, areaLabel,
mergeMethod="Max")
if
windMax > 50:
# Put wind phrase first
reorderList.append(("wind_withGusts_phrase", "weather_phrase"))
#
Apply any reorderings that were identified
for
name1, name2 in reorderList:
self.moveAbove(tree, component, name1, name2)
return
self.DONE()
"North winds 20 mph until 10 AM then 35 mph."
To accomplish this, override the flags below from the ConfigVariables module. Be sure that if you want higher temporal resolution in your phrase, to set the temporal resolution in the analysisList accordingly. For example:
("Wind", self.vectorMedianRange, [0]),
def
untilPhrasing_flag_dict(self, tree, node):
# If
set to 1, "until" time descriptor phrasing will be used.
# E.g.
"NORTH WINDS 20 MPH UNTIL 10 AM...THEN 35 MPH"
return
{
"otherwise": 0,
#"Wind" : 1,
}
def
onTheFly_untilPhrasing_flag_dict(self, tree, node):
# If
set to 1, "until" time descriptor phrasing will be used ONLY if
# the
time range for a sub-phrase does not end on a 3-hour boundary.
return
{
"otherwise": 1,
#"Wind" : 1,
}
def
untilPhrasing_format_dict(self, tree, node):
#
Format for "until" time descriptors.
# If
"military": UNTIL 1000
# If
"standard": UNTIL 10 AM
return
{
"otherwise": "military",
#"Wind": "standard",
}
The untilPhrasing may apply to only certain components of your product. You can make this distinction as in this example from the FWF:
def
untilPhrasing_flag_dict(self, tree, node):
# If
set to 1, "until" time descriptor phrasing will be used.
# E.g.
"NORTH WINDS 20 MPH UNTIL 10 AM...THEN 35 MPH"
# Be
sure to increase the temporal resolution if desired:
#
E.g. ("MixHgt", self.minMax, [0]),
dict =
TextRules.TextRules.untilPhrasing_flag_dict(self, tree, node)
dict["LAL"] = 1
componentName = node.getComponent().get("name")
if
componentName == "FirePeriod":
dict["Sky"] = 1
dict["Wx"] = 1
return
dict
Example 1:
Grids:
Hour 1-6
Patchy F 1/4SM Chc R 1/2SM
Hour 7-12 Sct RW
Phrase:
CHANCE OF LIGHT RAIN AND PATCHY FOG WITH VISIBILITY LESS THAN 1 NM THEN
SCATTERED RAIN
SHOWERS IN THE AFTERNOON.
Example 2:
Grids:
Hour 1-6
Patchy F 1/4SM Chc R 1/2SM
Hour 7-12 Sct RW
11/2SM
Phrase: CHANCE OF LIGHT RAIN AND PATCHY FOG WITH VISIBILITY LESS THAN 1 NM THEN SCATTERED RAIN SHOWERS WITH 2 NM VISIBILITY IN THE AFTERNOON.
The wording for visibility within the weather phrase can be configured by overriding the visibility_weather_phrase_nlValue.
You can set the null_nlValue for "Visibility" so that only visibilities below the threshold are reported. The value should be in nautical miles. Suppose we have set this value to 3 nautical miles, Then:
Example 3:
Grids:
Hour 1-6
Patchy F 4SM Chc R
Hour 7-12 Sct RW
Phrase:
CHANCE OF LIGHT RAIN AND PATCHY FOG THEN SCATTERED RAIN SHOWERS IN THE
AFTERNOON.
You can set the visibility_wx_threshold so that weather is only reported if visibility is below the threshold. Also, in this case you might want to set up a list of significant_wx_visibility_subkeys. If any of these subkeys appear in the sub-phrase, the weather will be reported regardless of the visibility. Suppose we have:
def
visibility_wx_threshold(self, tree, node):
#
Weather will be reported if the visibility is below
# this
threshold (in NM) OR if it includes a
#
significant_wx_visibility_subkey (see below)
return
3
def
significant_wx_visibility_subkeys(self, tree, node):
#
Weather values that constitute significant weather to
# be
reported regardless of visibility.
# If
your visibility_wx_threshold is None, you do not need
# to
set up these subkeys since weather will always be
#
reported.
# Set
of tuples of weather key search tuples in the form:
# (cov type inten)
#
Wildcards are permitted.
return
[("* T"), ("* ZY")]
then:
Example 4:
Grids:
Hour 1-6
Patchy F 1/4SM Chc R 4SM
Hour 7-12 Sct RW
Phrase: CHANCE OF LIGHT RAIN AND PATCHY FOG WITH VISIBILITY LESS THAN 1 NM IN THE MORNING.
Example 5:
Hour 1-6 F 1/4SM RW
1/2SM
Hour 7-12 TRW
Phrase: CHANCE OF LIGHT RAIN AND PATCHY FOG WITH
VISIBILITY LESS THAN 1 NM THEN SCATTERED SHOWERS AND
THUNDERSTORMS IN THE AFTERNOON.
Finally, there is a consolidation method (consolidateVisibility in WxPhrases). If the low visibility is constant across sub-phrases, visibility is separated out into its own phrase:
Example 6:
Hour 1-6 F 1/4SM RW
1/2SM
Hour 7-12 TRW 1/4SM
Phrase: CHANCE OF LIGHT RAIN AND PATCHY FOG THEN SCATTERED SHOWERS AND THUNDERSTORMS IN THE AFTERNOON. VISIBILITY LESS THAN 1 NM.
The wording for visibility within the
visibility_phrase can be configured by overriding the visibility_phrase_nlValue.
If you always want visibility reported in its own phrase, you can
include the visibility_phrase in your
phrase list ANDmake sure to set the embedded_visibility_flag to zero so that it does not appear redundantly within
the weather phrase.
def
combine_T_RW(self, subkey1, subkey2):
#
Combine T and RW only if the coverage of T
# is
dominant over the coverage of RW
wxType1 = subkey1.wxType()
wxType2 = subkey2.wxType()
if
wxType1 == "T" and wxType2 == "RW":
order = self.dominantCoverageOrder(subkey1, subkey2)
if order == -1:
return 1, subkey1
return
0, None